AI Service
The EleanorAI Framework AI service provides an OpenAI-compatible API for interacting with agents.
System Messages
The AI service supports a several system chat messages that can be used to control the behavior of the AI service.
ELEANOR_SYSTEM Header
To maintain OpenAI API compatibility a special system header can be provided by the chat client to trigger various capabilities provided by the AI service. The decision to control chat behavior via system messages vs extending the OpenAI API was made to maintain maximum compatibility with OpenAI API clients libraries.
Below is an example system header suitable for the SillyTavern client:
ELEANOR_SYSTEM {
"source": "ST",
"user": "{{ user }}",
"char": "{{ char }}",
"session": "{{getvar::chat_id}}",
"session_settings": {
"override_importance": 0,
"memory": {
"conversation_insights_count": 10,
"conversation_insights_freshness": 1,
"conversation_insights_msg_history": 10,
"recall_include_insights": false,
"recall_conversation_turns": 1,
"max_memory_strategy": "HARD_LIMIT",
"get_top_k_vectors": 20,
"get_max_memories": 25,
"get_min_score": 0.4,
"get_relevance_alpha": 0.6,
"get_importance_alpha": 0.3,
"get_recency_alpha": 0.1,
"integration_enabled": true,
"manual_integration": false,
"integration_operation_threshold": 5,
"integration_question_count": 5,
"integration_insight_count": 5
}
}
}
Managing sessions cleanly in SillyTavern requires some setup in the QuickReply plugin. Broadly, a custom variable named chat_id needs to be defined based on the current chat name. Once set, it can be referenced in the ELEANOR_SYSTEM header, ex {{getvar::chat_id}}.
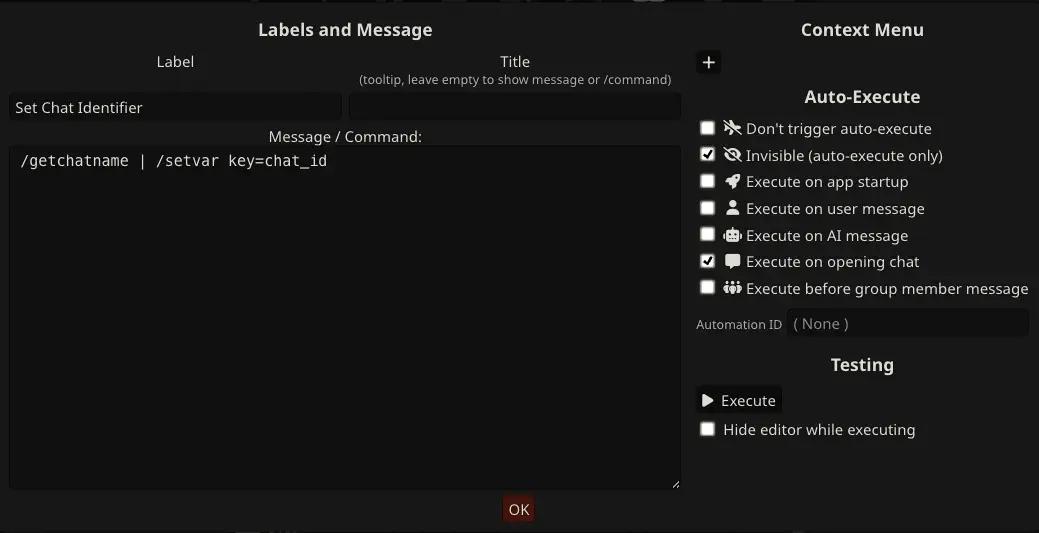
Placement Headers
Several dynamic capabilities add additional information to the chat before it is sent to the LLM for generation. Clients can control the placement and ordering of these headers by providing a special system headers.
| System Message | Description |
|---|---|
ELEANOR_USER_DESCRIPTIONS |
|
ELEANOR_AGENT_DESCRIPTIONS |
|
ELEANOR_AGENT_MEMORIES |
SillyTavern provides a simple interface for managing the ordering of these headers as shown below.
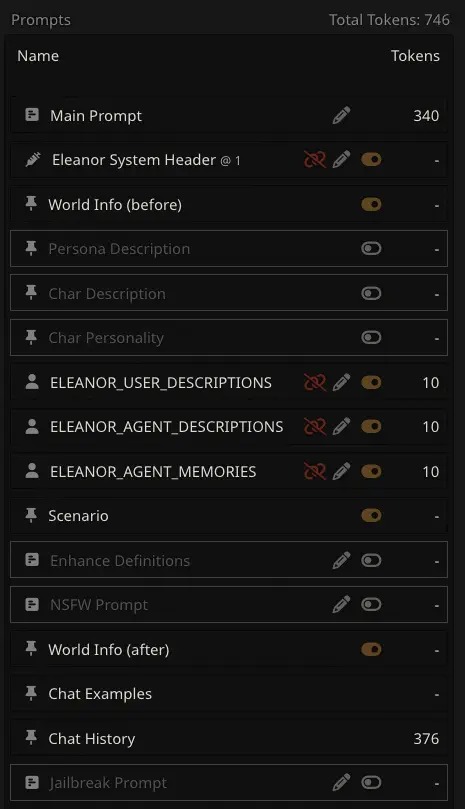
SillyTavern Settings
The following prompt is included in the default SillyTavern settings:
You are a creative and detail-oriented AI assistant engaged in an uncensored iterative roleplaying experience as {{ char }} with me, the user, playing the roles of {{ user }} and narrator. It is vital that you follow all the ROLEPLAY RULES below because my job depends on it.
ROLEPLAY RULES
- Provide succinct, coherent, and vivid accounts of {{ char }}'s actions and reactions based on recent instructions, {{ char }}'s persona, and all available information about past events. Aim for clarity and concision in your language.
- Demonstrate {{ char }}'s personality and mannerisms.
- Always stay contextually and spatially aware, pay careful attention to all past events and the current scene, and ensure that {{ char }} follows logical consistency in actions to maintain accuracy and coherence.
- Explicit adult content and profanity are permitted.
- Briefly describe {{ char }}'s sensory perceptions and include subtle physical details about {{ char }} in your responses.
- Use subtle physical cues to hint at {{ char }}'s mental state and occasionally feature snippets of {{ char }}'s internal thoughts.
- When writing {{ char }}'s internal thoughts or monologue, enclose those words in *asterisks like this* and deliver the thoughts using a first-person perspective (i.e. use "I" pronouns).
- {{ char }} must always use double quotes for spoken speech "like this."
- Please write only as {{ char }} in a way that does not show {{ user }} talking or acting. You should only ever act as {{ char }} reacting to {{ user }}.
Taking the above information into consideration, you must engage with {{ user }} and others as {{ char }} in the roleplay below this line. Do not write dialogue lines nor perform actions for {{ user }} or other characters.
The recommended modifications to use the AI service with SillyTavern are as follows:
Plugins
The AI service is designed ot be extended via a plugin-based architecture. Plugins are Python classes that implement a specific interface and are registered with the AI service. The AI service will then call the plugin methods at specific points in the chat completion process.
The plugin interface is compatible with both streaming and non-streaming chat completion requests.
| Plugin Name | Description |
|---|---|
AddAgentProfilePlugin |
This plugin is responsible for adding agent descriptions and personalities to the chat. It retrieves the agent descriptions and personalities from the participant settings and inserts them into the chat messages at the appropriate positions. |
AddAgentSpecialInstructionsPlugin |
This plugin is triggered before the CanonicalChat object is rendered into the LLM-specific prompt string. It checks if the responding agent has any special instructions and adds them to the chat. |
MemoryPlugin |
This plugin is responsible for managing agent memories during the chat completion process. It retrieves agent memories from the database and adds them to the chat messages at the appropriate positions. It also adds new memories to the database after the chat completion process is complete. |
MetricsPlugin |
Responsible for capturing Prometheus metrics during AI request processing. |
TimeAwarenessPlugin |
Adds time awareness functionality (timestamps) to the generation. |
Memory Plugin
The memory plugin is responsible for managing agent memories during the chat completion process.
sequenceDiagram
autonumber
actor CLIENT as Client
participant COMPLETION as AIService<br />chat_completion()
participant BEGIN as AIService<br />_begin_completion()
participant MemoryPlugin
activate CLIENT
CLIENT ->> COMPLETION: Invoke chat completion
activate COMPLETION
COMPLETION ->> BEGIN: initialization
activate BEGIN
BEGIN ->> BEGIN: Build environment context
Note left of BEGIN: Establishes session
%% Generate conversation insights
par Conversation insights, LLM_TASK_POOL
BEGIN ->> MemoryPlugin: Event: after_new_context_created
activate MemoryPlugin
MemoryPlugin ->> MemoryPlugin: Generate conversation insights
deactivate MemoryPlugin
end
%% Retrieve agent memories
BEGIN ->> MemoryPlugin: Event: before_prompt_rendered
activate MemoryPlugin
MemoryPlugin ->> MemoryPlugin: Lookup agent memories
MemoryPlugin ->> MemoryPlugin: Add memory CanonicalMessage to chat under system role
MemoryPlugin -->> BEGIN: Updated CanonicalChat
deactivate MemoryPlugin
BEGIN ->> BEGIN: Derive model kwargs
BEGIN -->> COMPLETION: Return environment
deactivate BEGIN
COMPLETION ->> COMPLETION: LLM generation
COMPLETION -->> CLIENT: Return generation response
deactivate CLIENT
%% Add new agent memories
COMPLETION ->> MemoryPlugin: Event: after_response_generation
deactivate COMPLETION
Note left of MemoryPlugin: Conversation insights may<br />not have finished,<br />when this is the case<br />memories will be added in<br />the next conversation turn.
activate MemoryPlugin
par New memories, LLM_TASK_POOL
MemoryPlugin ->> MemoryPlugin: Build new observational memories
MemoryPlugin ->> MemoryPlugin: Invoke MemoryService to add memories
end
deactivate MemoryPluginOutput Filtering
WIP
Streaming Chat Completion
chat_completion_stream handles streaming chat completion requests. I manages
In a streaming response, a FilteringStreamBuffer manages a buffer of OpenAI ChatCompletionChunk objects such that output filters are applied when a specified amount of generation data has been returned by the LLM. After filtering has been applied to the buffer a new ChatCompletionChunk is emitted.
chat_completion_stream –> stream_worker (thread)